
引言
无论是从搜索引擎的搜索指数,还是社交媒体的日常推送,我们都可以发现:2022年后半年,“AI绘画” 在互联网中的讨论度大幅升高。
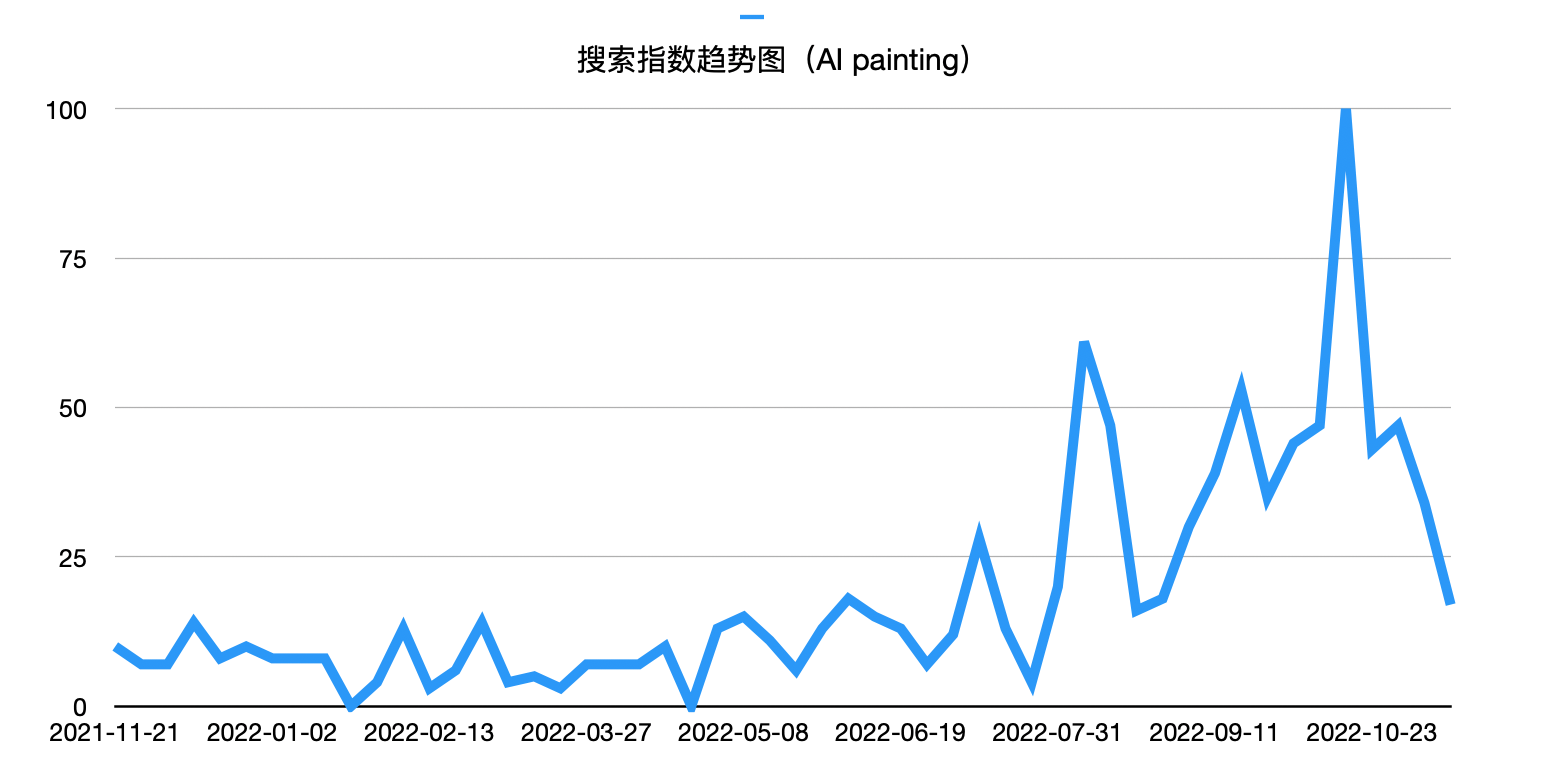
AI绘画是如何一步步发展到今天的?发展过程中涉及到哪些关键技术?这些关键技术的基本原理又是怎样的?
先从AI绘画的历史说起
AARON
在上世纪70年代,艺术家、工程师哈罗德・科恩打造了一款名为AARON的人工智能绘画系统,此后的几十年中,科恩都在不断地对AARON进行改进。诞生之初,AARON只能通过控制现实中的小型机器人,绘制出简单黑白图案,在经过近十年的改进后,AARON已经能够通过机械臂绘制出彩色的、稍显复杂的图案。而到科恩去世的2016年,AARON甚至能够通过电脑屏幕实时地显示绘画结果。

早期的AARON绘画系统,通过小型机器人在画布上创作
1980年,AARON的作品,只能有一些简单的黑白图案


1995年,能够绘制彩色作品的AARON绘画系统

1995年,AAPON创造的第一幅彩色作品
在现在看来,这样的人工智能未免过于古早,绘制的作品也局限于抽象、意象派的风格,与如今风格百花齐放的AI绘画相比略显单调。
而如今我们接触的AI绘画,还要从2012年后深度学习的爆发说起。
AI绘画的真正开始
2012年,来自google的人工智能研究员jeff dean领导团队,搭建了彼时最大的人工神经网络之一(拥有约10亿个神经元),并提供了约1000万张youtube视频缩略图供该神经网络深度学习(类似于人类大脑的学习过程)。在没有研究人员引导的情况下,该人工神经网络自行创建了“猫”的概念,并能够在这约1000万张缩略图中以较高的识别率(74.8%)识别出“猫”。
随后,研究人员利用了可视化技术,将该人工神经网络认为的“猫”可视化。

该人工神经网络脑中的“猫”
即使图片的细节仍不尽人意,但也正是彼时的这一副作品,确定了AI绘画发展的大致方向:巧妙的训练算法与规模庞大的数据集。
自2012年起,越来越多的学者进军深度学习领域。在2014年,Ian Goodfellow等学者发表了论文《Generative Adversarial Nets》,为人工智能如何高效利用数据自我提升(即人工智能训练)提供了绝佳的新思路,并在随后的2016年掀起了一波深度学习的高潮,也使得AI的绘画能力大幅提升。
那么,生成式对抗网络(Generative Adversarial Nets, GAN) 是以什么样的机制,为人工智能的发展提供新思路的?
生成式对抗网络(GAN)
让我们先回忆一下:我们一般是如何学习写字的?
在小学或者更早的时候,我们也许是这么干的:课后,我们先凭借自己的大概印象,在作业本上书写,然后再将我们的作品与教科书上的范例进行比较。如果写(或者说画)得比较像,就代表我们掌握了这个汉字的写法,否则,我们就得不断地进行修正,直到我们写得与范例大致相同。
这个过程中,可以抽象出两个主要对象:我们脑中负责生成汉字的神经网络,以及负责比较我们自己生成的汉字与范例汉字之间差别的神经网络(众所周知,我们的大脑中拥有一张张庞大的神经网络)。在不断地练习写汉字的过程中,我们写汉字的能力得到了提升,同时,我们判断汉字是否标准的能力也得到了提升。
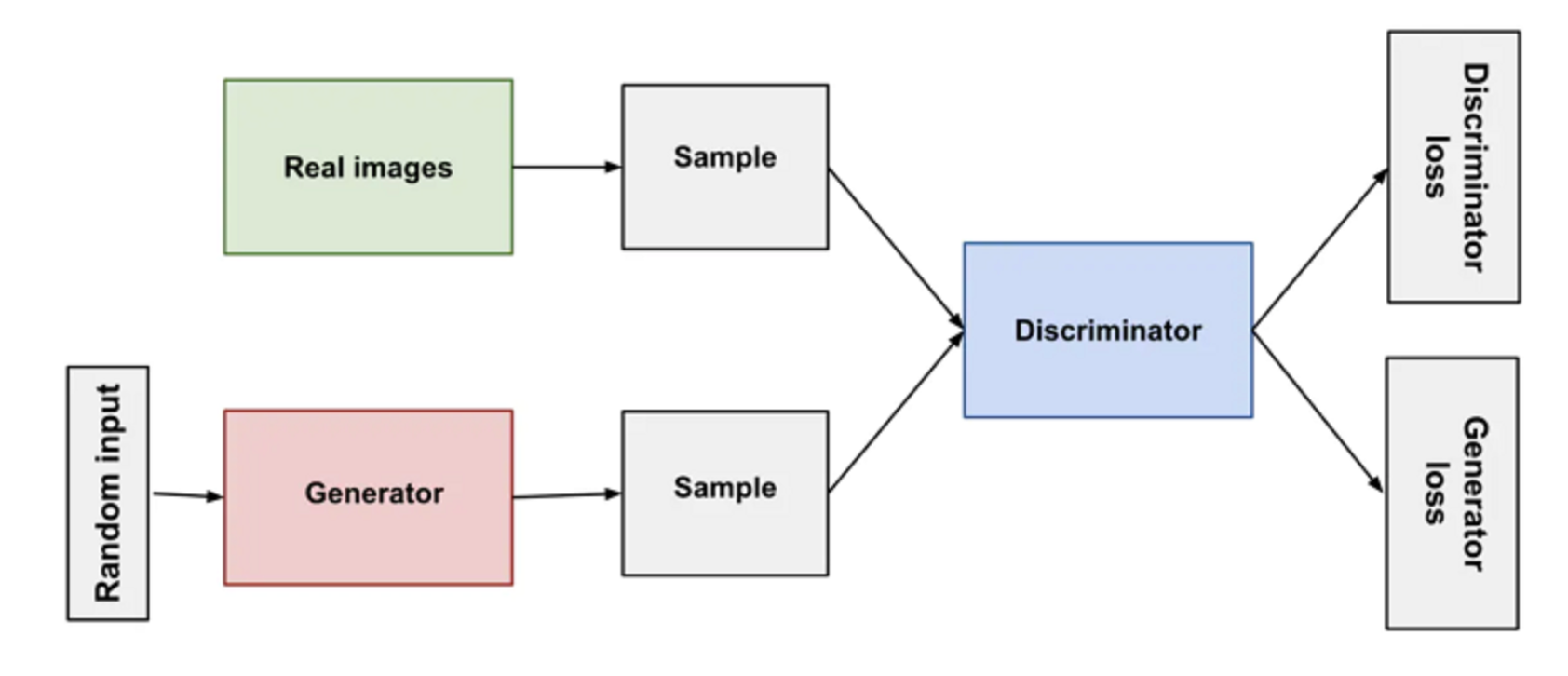
生成式对抗网络(GAN)大致上也是这样的思路——对抗学习。在一个生成式对抗网络中,有两个主要对象:生成器(Generator)以及判别器(Discriminator),分别对应我们上面写汉字的神经网络,以及判断汉字写得好不好的神经网络。
在生成式对抗网络训练的过程中,生成器会根据特定要求(比如一个描述图像特征的文本),生成一个图像的概率分布,与此同时,我们拥有该特定要求的标准答案。由于我们的最终目的是让生成器生成的东西尽可能地接近我们的标准答案。于是,我们把生成器生成的东西连同标准答案,一起扔给判别器。这时候,判别器就需要对生成器生成的东西进行评估:这东西到底是我们的标准答案,还是生成器生成的东西?如果判别器错误地将生成器生成的东西判别为了标准答案,判别器就需要纠正自身错误,得到提升;如果判别器正确地将生成器生成的东西识别出来,则说明生成的东西还不够接近我们的标准答案,生成器便需要改进自身不足,得到提升。
该过程的图形表示如下:
这样的机制实在是太聪明了!甚至于连获得过图灵奖的杨立昆都称GAN为“近二十年来机器学习领域最酷的想法”。
那么,基于GAN的人工智能,究竟能为我们带来什么呢?
文字 —> 图像 转换
首先是我们当下最火的“文字 -> 图像 转换”,即输入文字,让AI帮我们把图片画出来。
例如,我们想要一张拥有渐变色的小鸟的图片,基于GAN的人工智能的实现效果如下:

生成以假乱真的图像
在GAN训练模型进一步改进后,我们可以生成让人难以辨别真伪的图片:

当然也有以假乱真的真人图像:

生成二次元图片
GAN不仅能生成媲美现实照片的图像,还能生成二次元图像!甚至还可以准确学习各时期日本动画的流行画风!

(尽管有些人物的五官不尽协调,但还是GAN得不错!)
生成不同年龄的真人图像
也许你也在广告中看过诸如“测测你老了之后是什么样子”的内容,其背后的一种实现思路便是利用GAN:

除了以上列举的应用,在经过无数学者的研究后,GAN能干的还有很多,如:图像编辑、图像分辨率提升、图像修复、图像转文字……
GAN真的完美了吗?
诚然,GAN能做的有很多,生成的作品也足以让人惊叹,但跟如今的AI绘画比起来,好像还是差点意思。
比如,今年十月在中国爆火的NovelAI,其生成的作品是这样的:

无论是图像分辨率、画面精细度、场景丰富度都比GAN生成的更胜一筹,并且并不会像GAN生成的作品那样容易崩坏:

使用基于GAN的人工智能时,你可能会生成这样的图像
又比如,通过现在的AI可以很容易地生成大师风格的作品:

一只日出时坐在田野上的狐狸,莫奈风格
再比如,如今的AI生成一些充满想象力的场景图像也不在话下:

在亚马逊雨林中的乌托邦太阳城
而GAN最擅长的真实图像领域,如今的AI也能做到:

这些图像都根据文本描述生成,因此AI绘画于普通人而言变得空前地容易。
要实现这样的效果,如果仅仅是停留在对GAN模型的改进上显然是不行的。原因很明显:
- GAN要同时训练两个网络(生成器和判别器),训练的效果不稳定,模型容易坍塌
- GAN生成图像的主要目标是“真实”而非“多样”,因此生成图像的创作性不足
- GAN的生成工作都在神经网络中隐式完成,并不属于概率模型,在数学方面的可操作性不足(不够优美)
于是,要让AI绘画的质量大幅度增强,一种新的生成模型显得尤为必要。
扩散模型
在本篇中,我们并不会涉及到任何具体的数学推导。
扩散模型(Diffusion Model)命名的灵感来源于热力学。在伟大的高中里我们知道:在一个体系中,物质分子会从高浓度区域向低浓度区域转移直到均匀分布。

而在图像生成领域,我们也可以复现类似的现象:

随着时间推移,噪声不断增加,且该噪声均匀地“扩散”在图片中
正如上图所示,从左往右看,我们在不断地添加噪声“破坏”图像,最终,当时间趋于无穷,我们的图像也收敛于纯噪声。(该过程被称为前向扩散)
但是,只要我们从右往左看,就是在一点点地去除噪声。如此这般,最终不就能从纯噪声“还原”出我们想要的图像了吗?(该过程被称为逆向降噪)
扩散模型基本原理就是这么地简单,其实,该模型真正的难点在于如何“去噪”。
值得高兴的是,在前向扩散的过程中,我们加入的噪声都是服从于正态分布(高斯分布)的,并且该噪声如何添加,取决于当前图像的样子。于是,根据我们已有的图像,我们就可以优美地用数学表示每一步的噪声,并根据已有的图像与噪声,计算出下一步的图像。与之相对,在逆向降噪的过程的每一步,我们已有的只是一张含有噪声的图像,但只要利用深度残差网络预测(也就是猜)出噪声是多少,就可以根据当前的图像与噪声,倒推出上一步的图像。在经过一步步的降噪后,我们便通过纯噪声顺利地得到我们想要的图像。
选择性阅读:
实际上,扩散模型的实现细节千变万化,关于对扩散模型进行改进的论文也数不胜数。例如,上面我们提到的做法是利用深度神经网络预测每一步的噪声,但由于每一步噪声都是服从于正态分布的,我们便可以锁定它的方差,只预测它的均值(DDPM中的做法);也可以对均值与方差都进行预测(Improved DDPM中的做法)。进一步地,我们可以再训练一个神经网络,引导噪声预测的方向,提高图像生成的保真度(Diffusion Models Beat GANs中的做法)。此外,我们也可以不对噪声进行预测,而是直接对上一步的图像进行预测(DALLE 2的做法)。还有很多很多的实现细节与技巧,读者在掌握了高等代数、数学分析、概率论的知识后,可以尝试在各种相关论文中一探究竟。
在了解了基本的原理之后,如果你不打算看论文了解实现细节,就让我们来看看基于扩散模型的AI绘画应用主要有哪些吧!
NovelAI
如今谈到AI绘画,就不得不谈到NovelAI。于2022年10月3日推出图像生成服务后,NovelAI在中文互联网以一己之力大幅地提高了“AI绘画”的讨论度。一时间,无数的二次元绘画作品涌现。
通过NovelAI你可以生成媲美人类画师的作品:

也可以生成一些稍显荒谬的作品:

要使用NovelAI也相当简单,只需要进入他们网站中的图像生成器,输入提示词(Prompt),调整一些参数,便可以得到一副独一无二且属于你的画作。
注意:该功能为付费功能,需要充值代币使用
Midjourney
在探讨AI绘画伦理问题时,大概率会提到下面这幅作品:

《太空歌剧院》
在2022年的美国科罗拉多州艺术博览会上,一位绘画水平不如专业画师的游戏设计师,利用该画作击败了一众人类画师,并最终获得数字艺术类别冠军。这背后显然牵涉到复杂的道德问题,但本文并不关注道德问题,而是将目光聚焦于生成该作品的AI:Midjourney。
与NovelAI不同,Midjourney只能在discord上使用。在进入Midjourney这一频道后,选中聊天机器人,通过 /imagine 指令开启图像生成模式。随后便可以输入关键词,得到对应的输出。
在生成过程中,Midjourney会根据你的关键词生成多幅低分辨率的作品供你挑选(此时,你大概只能看到画面的基本元素、基本构图)。挑选完成后,你可以选择生成该图片的高分辨率版本,以在画面中补全细节;也可以选择生成该图片的其他低分辨率版本,直至寻找到最符合你预期的作品。这一过程需要AI拥有足够大的创造力,但对于使用扩散模型的Midjourney来说,这不是问题。
通过Midjourney,人类得以方便快捷地生成艺术作品。感兴趣的读者可以点击链接进行尝试。
还有更多
NovelAI与Midjourney只是AI绘画的冰山一角,诸如此类的应用还有很多:如开源的Disco Diffusion、Stable Diffusion,通过这些开源的模型,你可以独立地使用AI绘画,且绘画作品的版权属于你自己。其他的如OpenAI推出DALL·E 2、Google推出的Parti,这类AI在对事物之间联系的理解能力达到了惊人的水平,生成的图像质量也十分让人震惊。但出于安全、伦理问题的考虑,这类AI模型并未开源,使用这些模型也需要预约等待。
扩散模型也并非只能在图像生成领域大展身手。在其他领域,如计算机视觉、NLP、波形信号处理、多模态建模、分子图建模、时间序列建模、对抗性净化上都有出色的表现。
结语
2017年,阿尔法击败当时的世界围棋冠军柯洁,彼时的人们,觉得AI不过是个会下棋的工具,对社会毫无影响。但随着AI的不断发展,小至抖音短视频配音,大至协助人类探索太空,AI已经在出行、餐饮、娱乐、金融、文化、教育、医疗等生活的方方面面为人类解放了大量的生产力。最近人工智能绘画的爆火,更是让人类刷新了对AI的认识。
身处当今时代的我们,似乎正面临着18世纪欧洲纺织工同样的苦恼,但也正是因为身处这个时代,我们得以拥有更丰富的信息来源、更强的接纳能力。如今这个被AI深刻影响的现代社会,不过始于若干年前实验室中研究员发表的一篇篇论文。AI何去何从,终究掌握在人类手里。