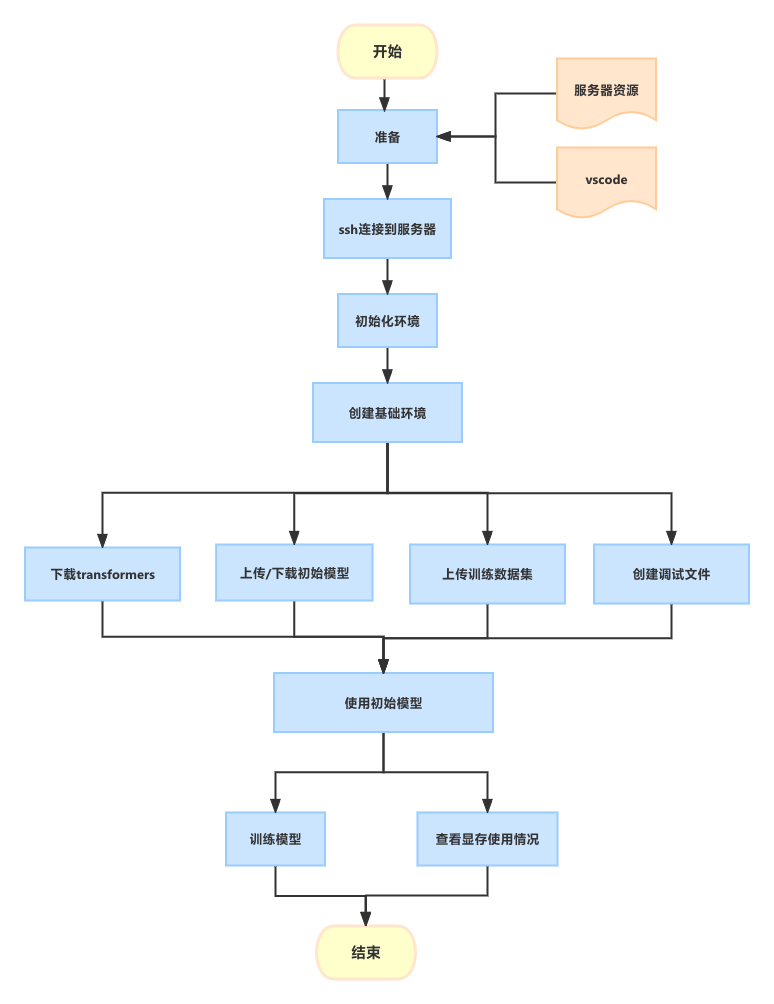
GPT-2 训练示例
目标:体验模型训练的过程。
流程:以GPT-2开源模型为初始模型,在服务器上使用txt格式的中文数据集,对初始模型进行训练。
简介:GPT-2开源模型只能使用英语进行问答,使用中文数据集训练后,GPT-2 可以使用中文回答。
准备
所需资源:
- 服务器资源(服务器地址,密码)
- vscode(用于ssh连接到服务器,调试运行),需要安装相关扩展包,比如
remote-ssh, python, Jupyter,isort,pylance等等。
ssh连接到服务器
打开 vscode,如果已经安装好 remote-ssh,点击左下角的><的标志。
点击 Connect to Host,然后输入服务器地址 ubuntu@xx.xxx.xx.xx(请输入真实服务器地址),点击回车键。
出现提示Enter password for $name@xx.xxx.xx.xx,在输入框中输入密码,点击回车键确认。

服务器已经准备好 pytorch 镜像。
pytorch 是 torch 的 Python 版本,是一个 Torch7 团队开源的 Python 优先的深度学习框架,提供两个高级功能:
- 强大的 GPU 加入 Tensor 计算,可以利用 GPU 的性能进行计算。
- 构建基于 tape 的自动升级系统上的深度神经网络,作为一个高灵活性,速度快的深度学习平台。
在这次训练中,我们需要 pytorch 利用GPU 性能进行计算的功能。比如,在后面“训练模型”章节提供的参考代码,选择处理器中,就使用了pytorch:
# 选择处理器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
初始化环境
conda 是开源软件包管理系统和环境管理系统,是一个辅助进行包管理和环境管理的工具,可以快速安装、运行和更新软件包及其依赖项。
初始化 conda:
conda init
创建基础环境
复制基础环境,并创建名为 gpt2 的虚拟环境(命名为 gpt2 是因为易于辨识,可以使用其他名称):
conda create -n gpt2 --clone base
创建环境可以在不同的项目使用不同的python版本和下载相关的包,a包需要特定版本的b包,但当前环境的其它版本b包需要使用,这时可以创建新环境来下载a包和依赖需要的b包。
如果报错NoWritableEnvsDirError: No writeable envs directories configured,可能是权限问题,需要调整。
先切换 root 权限:
sudo su
可以看到报错提示下会有几个文件路径,比如 /usr/local/miniconda3/envs。执行以下命令,调整权限:
sudo chmod 777 /usr/local/miniconda3/envs
退出 root 权限:
exit
即可再次执行命令,以复制基础环境:
conda create -n gpt2 --clone base
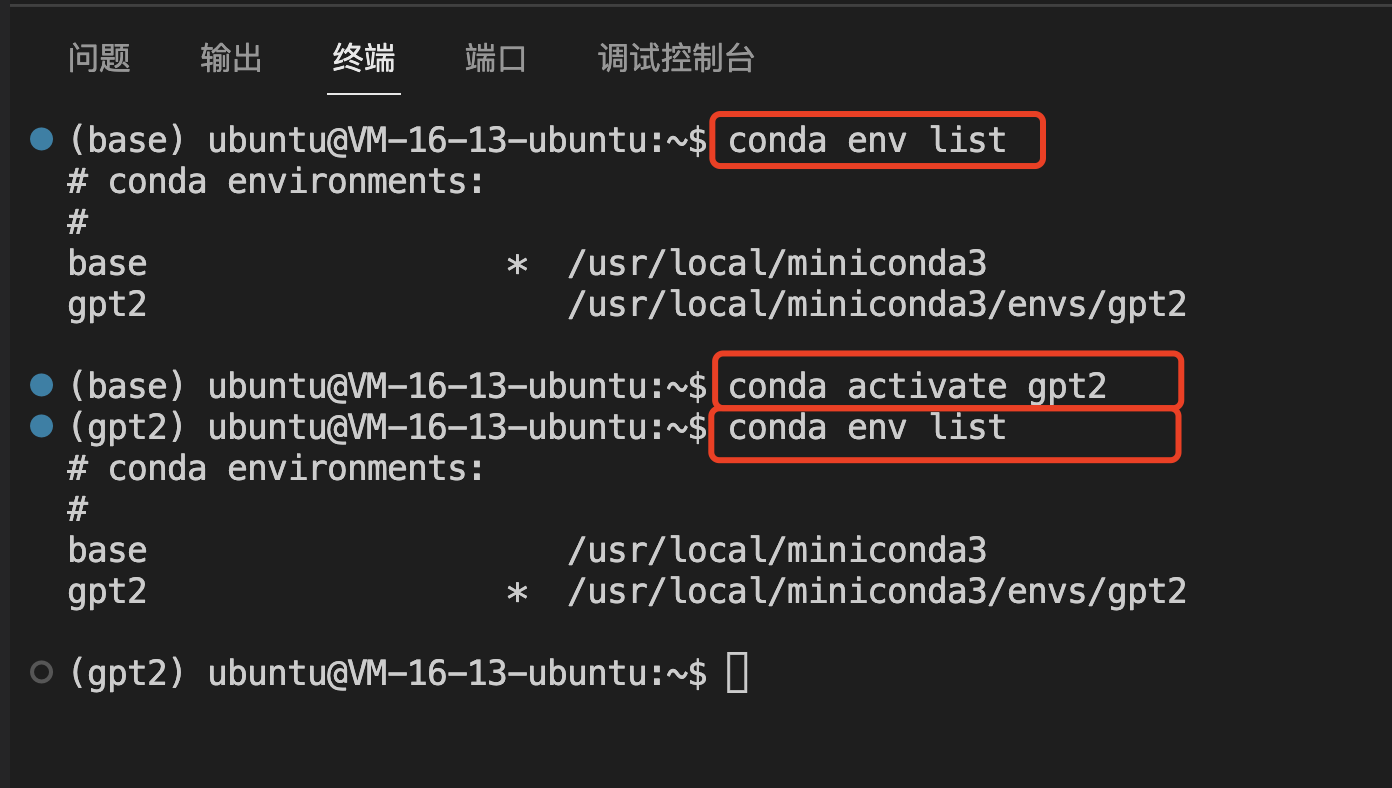
查看是否成功创建虚拟环境 gpt2:
conda env list
如果输出如下,则表示存在名为 base 和gpt2的两个环境,*表示当前处于 base环境:
# conda environments:
#
base * /usr/local/miniconda3
gpt2 /usr/local/miniconda3/envs/gpt2
切换到 gpt2 虚拟环境:
conda activate gpt2
再次执行命令:
conda env list
如果成功切换,则有如下输出,*表示当前处于 gpt2环境:
# conda environments:
#
base /usr/local/miniconda3
gpt2 * /usr/local/miniconda3/envs/gpt2
下载transformers
在服务器终端执行以下命令,下载 transformers:
pip3 install transformers
Transformer是一个利用注意力机制来提高模型训练速度的模型,里面主要有两部分组成:Encoder 和 Decoder。Transformer的特点是,完全利用attention机制来解决自然语言翻译问题。你可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。
在“训练模型”章节的参考代码中,Transformer 用于获取分词器和数据转换。
创建文件夹
在服务器创建两个文件夹,一个用于存放模型 model,一个用于存放训练数据 data。
这是非必要步骤,只是为了方便存放文件,让路径容易辨识。
mkdir model
mkdir data
查看是否成功创建文件夹,该命令会打印当前位置下的所有文件夹和文件:
ls
上传初始模型
在本地终端执行以下命令,上传本地训练数据集 /.../.cache/huggingface/hub/models--gpt2/snapshots/gpt2 到服务器 model文件夹 ubuntu@xx.xxx.xxx.xx:model。
注意,在本地终端执行命令,而不是在服务器终端。
注意,替换为真实的服务器地址和文件路径。
scp -r /.../.cache/huggingface/hub/models--gpt2/snapshots/gpt2 ubuntu@xx.xxx.xxx.xx:model
或,直接在服务器下载模型。
进入 model 文件夹:
cd model
下载模型的压缩包,并命名为 'gpt2.zip':
wget -O gpt2.zip "https://gpttrain-1307966650.cos.ap-guangzhou.myqcloud.com/models--gpt2.zip"
解压缩:
unzip gpt2.zip
解压后,查看当前文件夹:
ls
可以看到 model--gpt2 文件夹,进入该文件夹:
cd model--gpt2
查看 model--gpt2 文件夹:
ls
可以看到 blobs 文件夹,进入该文件夹:
cd blobs
打印当前位置的路径:
pwd
终端输出:
/home/ubuntu/model/model--gpt2/blobs
这就是我们要用到的模型路径,后面【使用初始模型】的代码,要用到这个路径。
最后,我们可以多次使用以下命令,返回上层文件夹,直到返回根目录:
cd ..
上传训练数据集
在本地终端执行以下命令,上传本地训练数据集 /.../Downloads/train.txt 到服务器的 data文件夹 ubuntu@xx.xxx.xx.xx:data。
注意,在本地终端执行命令,而不是在服务器终端。
注意,替换为真实的服务器地址和文件路径。
scp -r /.../Downloads/train.txt ubuntu@xx.xxx.xx.xx:data
创建调试文件
在根目录,创建文件 test.ipynb,这个文件的特别之处是,可以逐步执行代码,容易调试:
touch test.ipynb
以下提到的代码,都可以复制粘贴到该文件中调试运行。
如果已经创建好文件,下次可以直接在左侧选择“打开文件夹”选择该文件,打开文件:
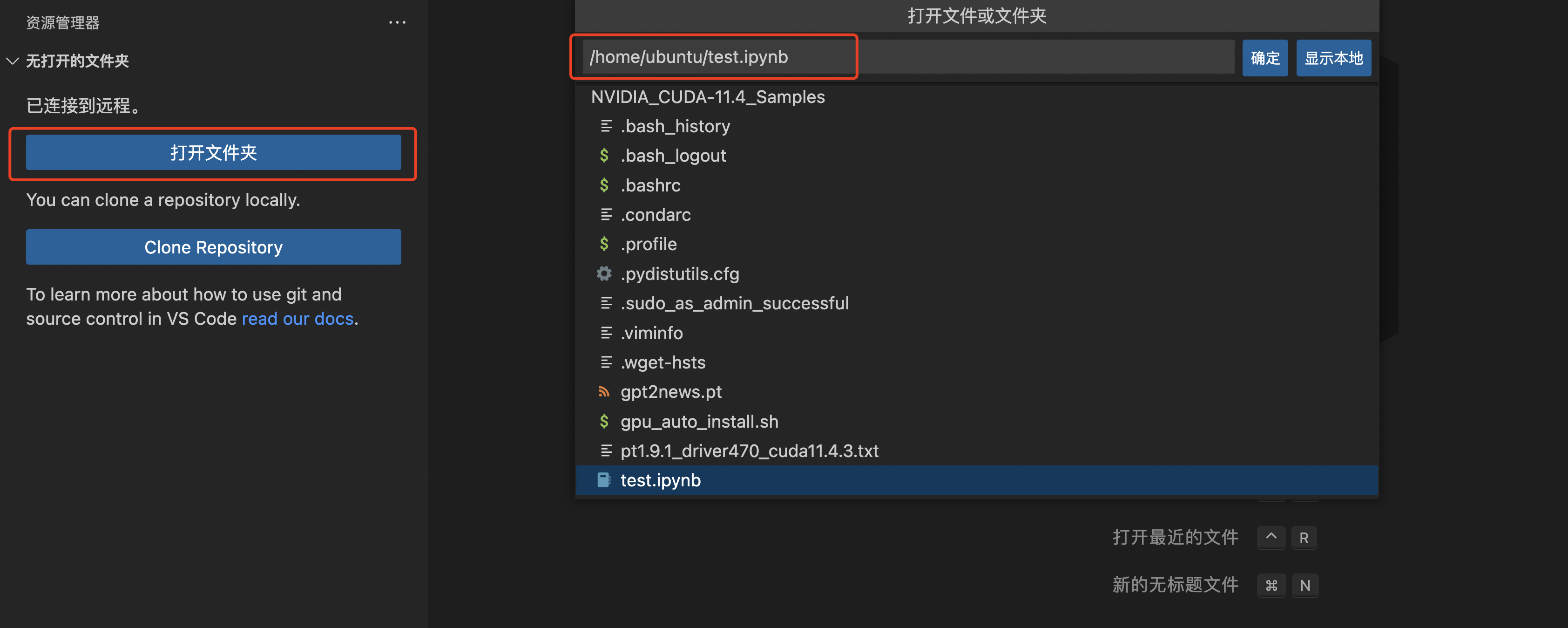
使用初始模型
尝试运行以下代码,作用是:使用初始模型来对话。若成功,可以进行下一步训练。
from transformers import GPT2Tokenizer, GPT2Model,GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('model/model--gpt2/blobs')
model = GPT2LMHeadModel.from_pretrained('model/model--gpt2/blobs')
text = "Replace me by any text you'd like."
input_ids = tokenizer.encode(text, return_tensors='pt', return_attention_mask = True)
print(tokenizer.decode(input_ids[0]))
greedy_output = model.generate(input_ids,max_length = 30,top_k=60,top_p=0.1,num_return_sequences=5,temperature=0.1,
num_beams=5,no_repeat_ngram_size=2,early_stopping=True,
pad_token_id=tokenizer.pad_token_id,eos_token_id=tokenizer.sep_token_id)
# print(tokenizer.decode(greedy_output[0], skip_special_tokens = True))
for i in greedy_output:
print(tokenizer.decode(i, skip_special_tokens = True)+'\n')
注意,将地址gpt2 替换为真实地址,即刚才上传初始模型的地址/服务器储存模型的地址。比如,模型放在以下位置:
/home/ubuntu/model/model--gpt2/blobs
因为文件 test.ipynb 在 /home/ubuntu 文件夹下,相关代码是这两行:
tokenizer = GPT2Tokenizer.from_pretrained('model/model--gpt2/blobs')
model = GPT2LMHeadModel.from_pretrained('model/model--gpt2/blobs')
将代码复制粘贴到 test.ipynb文件中,在右上角选择内核。
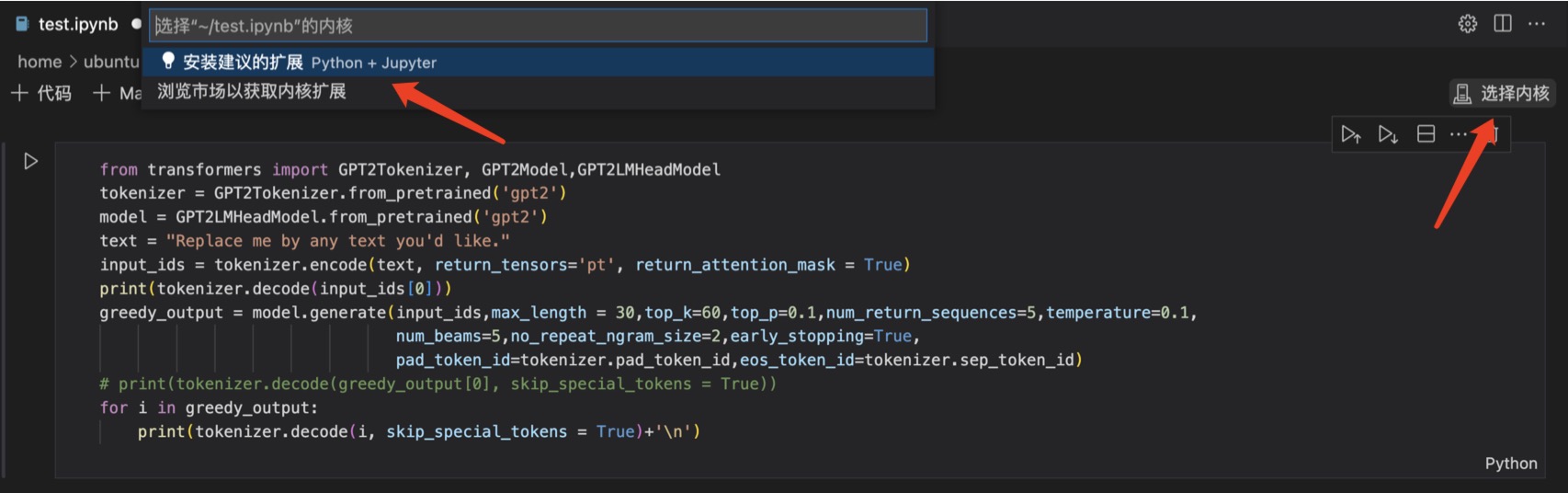
出现“安装建议的扩展”提示,一般是因为缺少相应的扩展包。根据提示去安装即可。
选择 gpt2 内核:
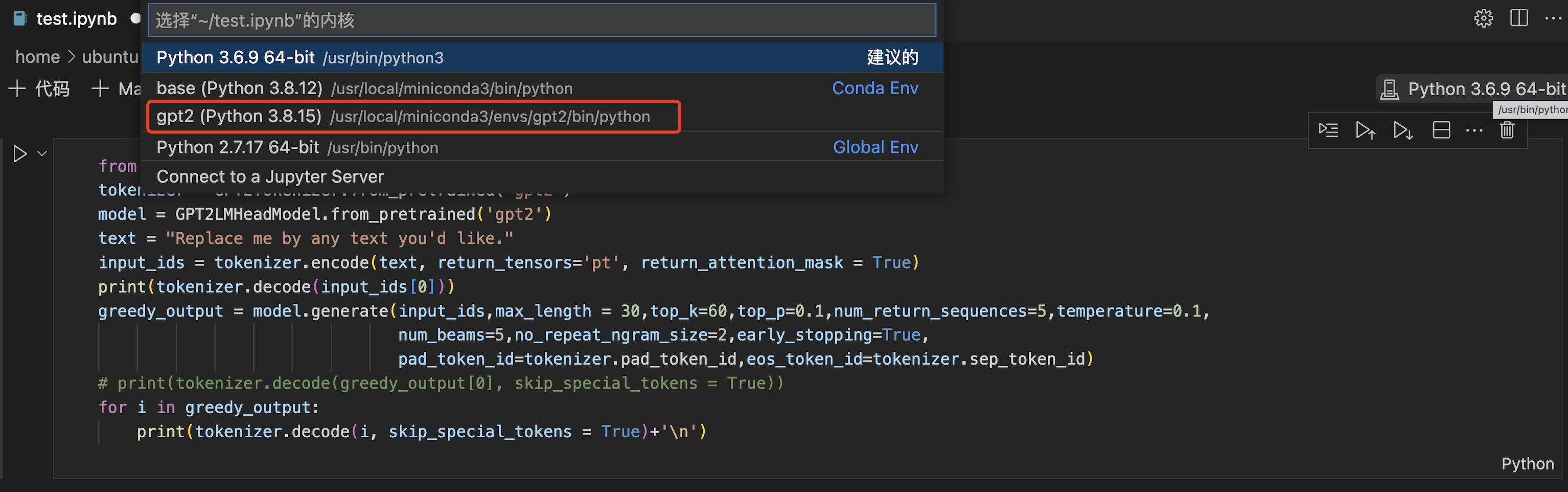
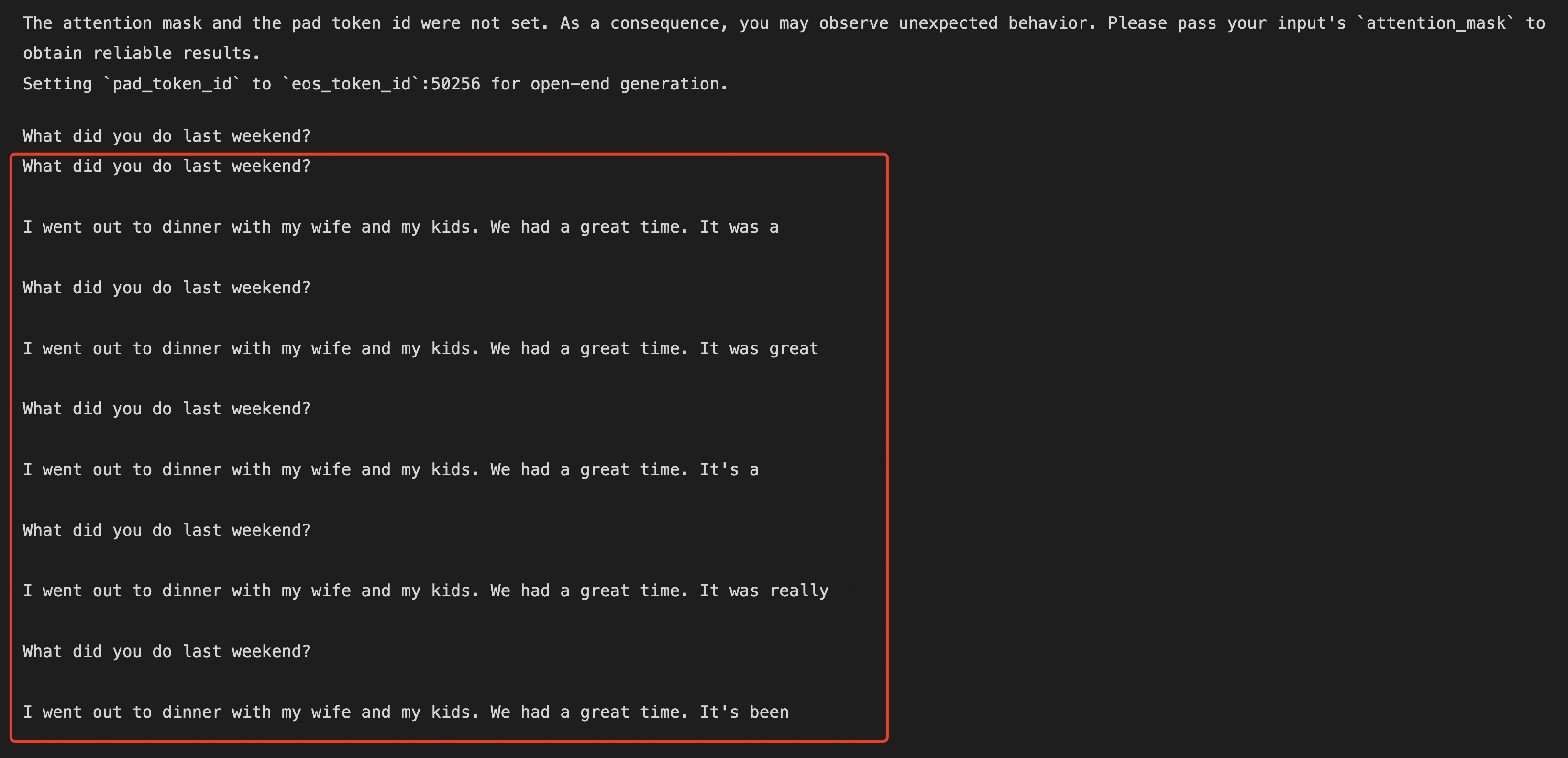
点击左侧的三角形,运行代码,在下方输出运行结果。
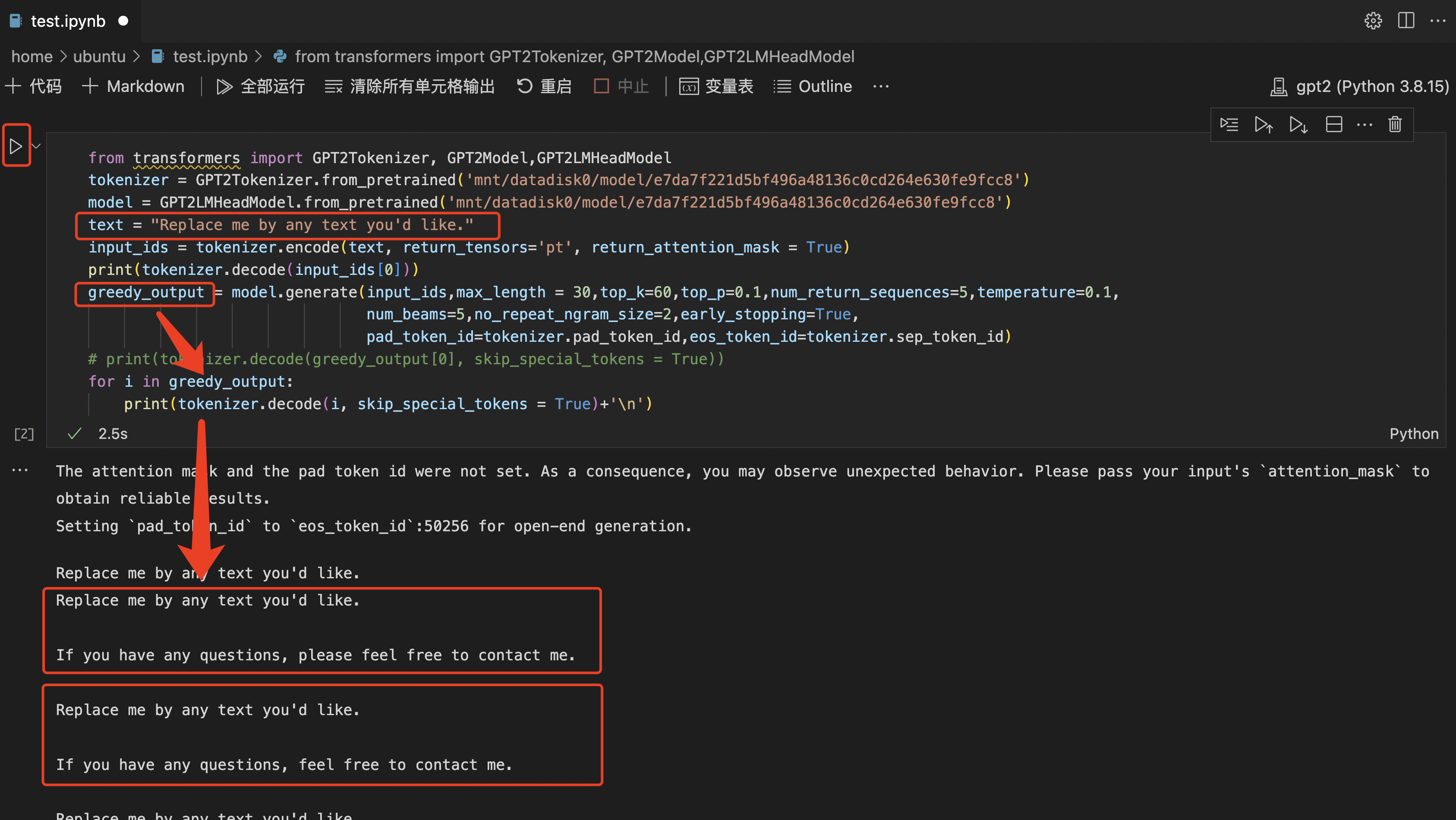
点击左侧的三角形,运行代码,在下方输出运行结果。
Q: What did you do last weekend?
A: I went out to dinner with my wife and my kids. We had a great time. It was a
A: I went out to dinner with my wife and my kids. We had a great time. It was great
A: I went out to dinner with my wife and my kids. We had a great time. It's a
A: I went out to dinner with my wife and my kids. We had a great time. It was really
A: I went out to dinner with my wife and my kids. We had a great time. It's been
训练模型
尝试运行以下代码,作用是:使用 txt 格式的训练数据集,来训练初始模型。
在训练模型时,可以逐段执行代码,便于调试。
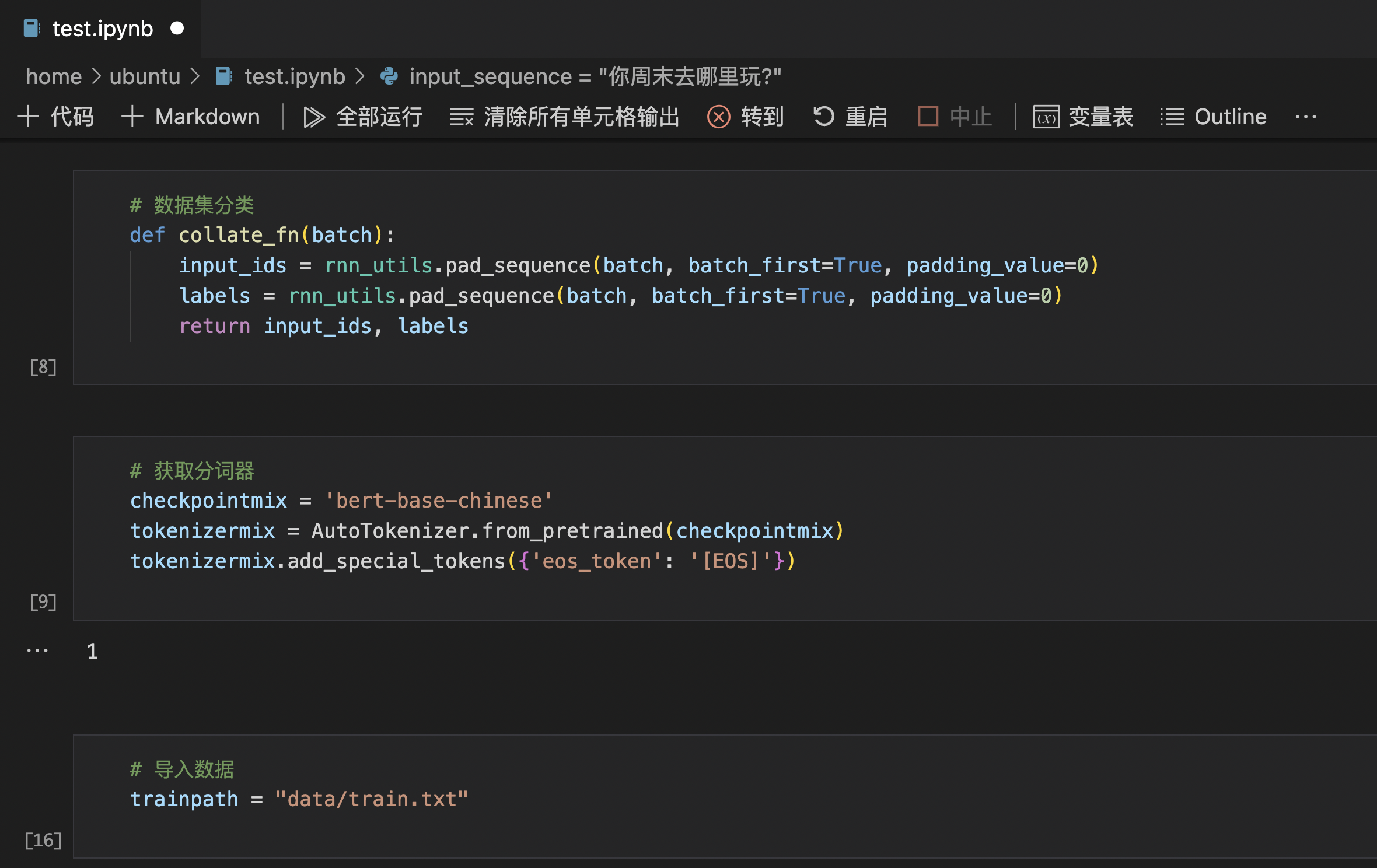
为方便理解,此处分段列出代码。
import json
import transformers
from transformers import GPT2LMHeadModel,GPT2Tokenizer,GPT2Config,GPT2Model
import torch
from torch.utils.data import DataLoader, TensorDataset
from torch import nn
from torch.autograd import Variable
import time
from transformers import AutoTokenizer
import numpy as np
from torch.utils.data import Dataset
import torch.nn.utils.rnn as rnn_utils
from torch.cuda.amp import autocast,GradScaler
# 创建数据集格式
class MyDataset(Dataset):
"""
"""
def __init__(self, input_list, max_len):
self.input_list = input_list
self.max_len = max_len
def __getitem__(self, index):
input_ids = self.input_list[index]
input_ids = input_ids[:self.max_len]
input_ids = torch.tensor(input_ids, dtype=torch.long)
return input_ids
def __len__(self):
return len(self.input_list)
# 数据集分类
def collate_fn(batch):
input_ids = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=0)
labels = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=0)
return input_ids, labels
# 获取分词器
checkpointmix = 'bert-base-chinese'
tokenizermix = AutoTokenizer.from_pretrained(checkpointmix)
tokenizermix.add_special_tokens({'eos_token': '[EOS]'})
注意,在导入数据集时,要使用真实路径,即上传训练数据集的文件路径。
# 导入数据
trainpath = "data/train.txt"
# 数据预处理
traindata = []
with open(trainpath,'rb') as f:
data = f.read().decode("utf-8")
if "\r\n" in data:
train_data = data.split("\r\n\r\n")
else:
train_data = data.split("\n\n")
# 数据转换
dialogue_len = [] # 记录所有对话tokenize之后的长度,用于统计中位数与均值
data_index = []
sep_id = tokenizermix.sep_token_id
cls_id = tokenizermix.cls_token_id
for dialogue in train_data:
input_ids = [cls_id] # 每个dialogue以[CLS]开头
if "\r\n" in data:
utterances = dialogue.split("\r\n")
else:
utterances = dialogue.split("\n")
for utterance in utterances:
input_ids += tokenizermix.encode(utterance, add_special_tokens=False)
input_ids.append(sep_id) # 每个utterance之后添加[SEP],表示utterance结束
dialogue_len.append(len(input_ids))
data_index.append(input_ids)
# 创建训练集
train_dataset = MyDataset(data_index, 70)
train_loader = DataLoader(
train_dataset, batch_size=64, shuffle=True,collate_fn=collate_fn,pin_memory=True,
drop_last=True
)
注意,在导入预处理模型时,要使用真实路径,即上传初始模型的文件路径。
# 导入预处理模型
GPT2 = GPT2LMHeadModel.from_pretrained('model/gpt2', pad_token_id=tokenizermix.pad_token_id)
# 选择处理器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
【训练模型】这一步耗时最长,需要等待一段时间。
其中,这段代码开头部分的epoch = 1控制训练的次数,初步设定为1。一般都需要经过多轮训练学习,才能取得较好的模型训练效果。
其中,这段代码最后的if (batch_idx+1)%100==0,可以控制训练过程中的打印频率。
# 训练模型
pre = time.time()
lasttm = time.time()
epoch = 1 # 循环学习 n 次
# GPT2 = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizercn.eos_token_id)
GPT2.to(device)
GPT2.train()
# optimizer = torch.optim.Adam(GPT2.parameters(), lr=1e-5) # 定义优化器
optimizer = torch.optim.AdamW(GPT2.parameters(), lr=1e-3)
accumulate_steps = 8
# scheduler = transformers.get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0.3*len(train_loader),num_training_steps=len(train_loader))
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,mode='min',factor=0.8,patience=10*accumulate_steps,verbose=True)
print('total batch:',len(train_loader))
scaler = GradScaler()
for i in range(epoch):
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(
target).to(device)
optimizer.zero_grad()
with autocast():
outputs = GPT2.forward(data,labels=target)
loss = outputs.loss
total_loss += loss
# outputs = GPT2.forward(data,labels=target)
# loss = outputs.loss
# total_loss += loss
# loss.backward()
# optimizer.step()
# scheduler.step(total_loss/(batch_idx+1))
scaler.scale(loss).backward()
if (batch_idx+1)%accumulate_steps==0:
scaler.step(optimizer)
optimizer.zero_grad()
scheduler.step(total_loss/(batch_idx+1))
scaler.update()
# scaler.scale(loss).backward()
# scaler.step(optimizer)
# scaler.update()
# scheduler.step()
if (batch_idx+1)%100==0:
print('batch_idx:', batch_idx+1,'time:', time.time()-lasttm,'loss:',total_loss/batch_idx+1)
lasttm = time.time()
if batch_idx == len(train_loader)-1:
# 在每个 Epoch 的最后输出一下结果
print('epoch:',i,'average loss:', total_loss/len(train_loader), 'epoch time:',time.time()-pre)
break
print('训练时间:', time.time()-pre)
# 保存模型
torch.save(GPT2.state_dict(),'gpt2news.pt')
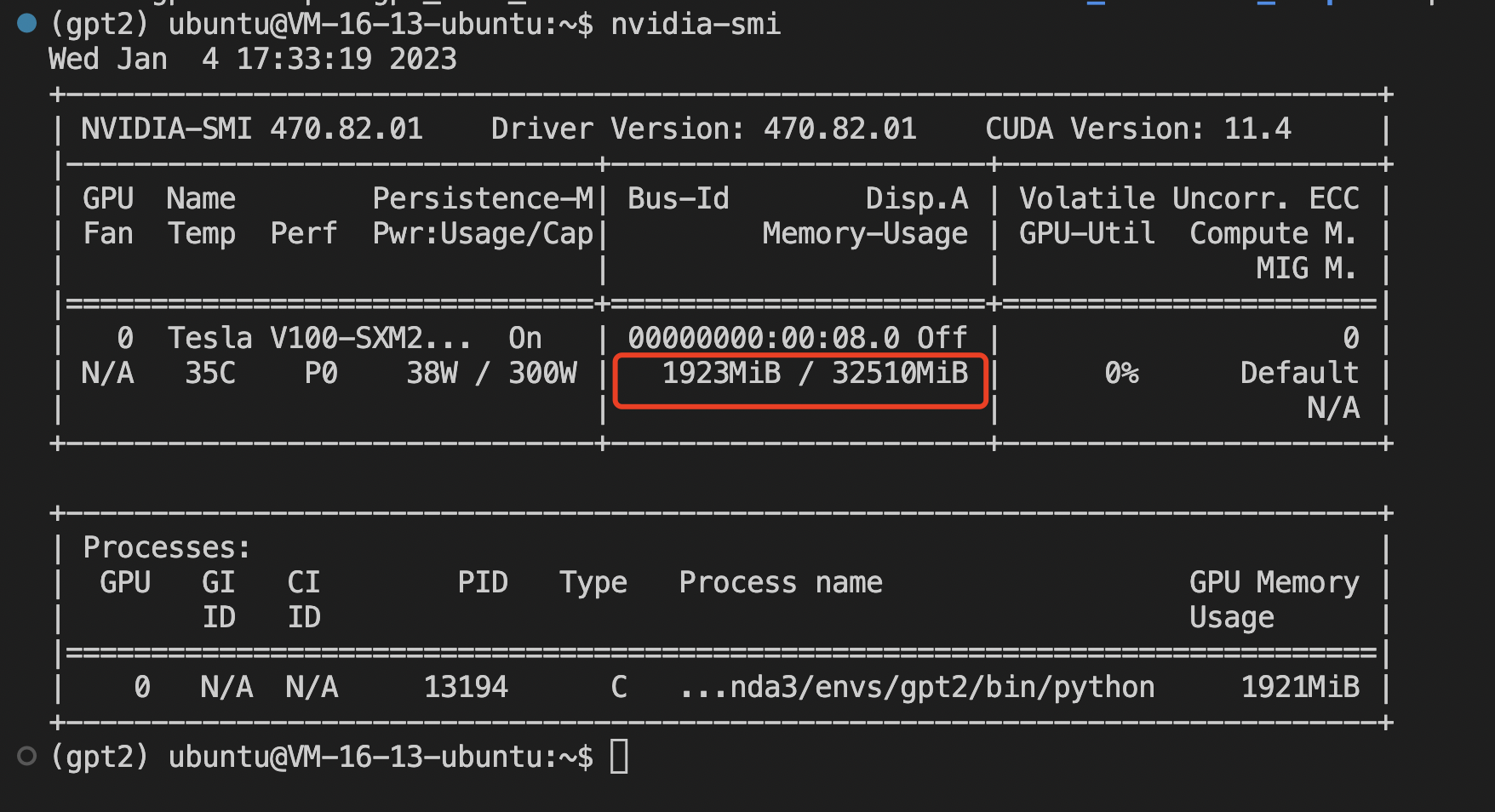
查看显存使用情况
在服务器终端输入以下命令,可以查看显存使用情况:
nvidia-smi
训练结果
按batch_size=64,训练100W数据(约100M)一轮,约耗时1小时,loss约为3.3587。
根据该数据集的经验,需要训练5-10轮,loss减小到1.9左右才有明显的训练效果。
其中,loss 会在训练过程中打印输出。
训练结束后,可以用以下代码查看训练结果:
input_sequence = "你周末去哪里玩?"
input_ids = tokenizermix.encode(input_sequence, return_tensors='pt', return_attention_mask = True).to(device)
GPT2.to(device)
print(tokenizermix.decode(input_ids[0]))
greedy_output = GPT2.generate(input_ids,max_length = 30,top_k=50,top_p=0.2,num_return_sequences=5,temperature=0.2,num_beams=5,no_repeat_ngram_size=2,early_stopping=True,pad_token_id=tokenizermix.pad_token_id,eos_token_id=tokenizermix.sep_token_id)
# print(tokenizermix.decode(greedy_output[0], skip_special_tokens = True))
for i in greedy_output:
print(tokenizermix.decode(i, skip_special_tokens = True)+'\n')
其他格式的数据集
上述例子中,我们使用了 txt 格式的数据集进行训练。如果使用其他格式的数据集,则需要调整【数据预处理】和【数据转换】两段代码。
总结